
At Sendinblue, we send billions of emails per month. Keeping our services up and running and ensuring our customers’ businesses are not impacted is not an option. No one, even FAANG companies, escapes outages. An email must go through different services before it lands in the user mailbox. It happens that one (or many) of these layers fail and disrupt partially or totally the Outbound Email delivery. In this article, we will drive you through our journey of building SIMA (Slack Incident Management Application), learning from our outages and streamlining our responses to incidents to make Sendinblue a world-class platform.
SIMA and this article are highly inspired by a ManoMano Tech team’s article: Incident Management with a bot
Problem statement
Prior to SIMA, incident responses (diagnosis, discussions, etc…) were happening in single massive Slack threads.
Most of the time, incidents’ timelines were shaped that way:
- a slack message posted in a production issues-related channel (either from Customer Care or engineering team members)
- reporters were posting updates within a slack thread until the issue has been fixed
- eventually, post mortem was written and actions taken
The thread approach can work in a small organization (or for small incidents) but the more complex or longer the incident is the harder it is to keep up. It became obvious we were not suited to respond to production incidents.
We pulled ourselves together and identified some bottlenecks:
- no clear and streamlined way to declare an incident. We had a Slack workflow but it was not much used
- to getting up to speed when you join an incident later took a lot of time and effort (reading a 100 messages thread is time-consuming)
- post-mortems were not systematically created. We strongly believe they are key to improving and communicating (internally and externally) as they help us
- no root cause tracking: knowing your weakness is not an option
- Nobody tracked MTTR. We had no standard way to record the start and end time of the incident
- internal communication was okay but we knew we could do better
These bottlenecks and the fact that Sendinblue’s team and customers list were growing (and still) at a fast pace was impacting our ability to manage incidents efficiently. For that reason, we decided to re-think our incident responses. We started building SIMA to help us improve on multiple aspects: resolution, communication, and analysis.
What is incident management?
Incident management is the process of managing disruptions, responding to unplanned events or service interruptions, taking actions to restore the services to its operational state and ensuring all the stakeholders involved are well informed about each stage of the incident timeline. Incident management is a very common practice in the software industry and companies follow it to mitigate the business impact. It triggers when an incident happens and ends when an incident is recovered.
The incident metrics
You can’t improve what you don’t measure
We had to change the way we were managing incidents so that we can learn from them and, even better, take advantage of them. We strongly believe that the reliability of our platform is key to the success of our customer’s business. Everyone dreams of 100% availability but it is nearly impossible to achieve it (at a reasonable cost and effort). Knowing that we all have to embrace failure and try to achieve the slowest downtime possible.
Creating/saving the metrics
We wanted to approach our incident management the same way as SRE does for every system: create metrics and use them to get better.
Every time an incident is raised, we request the reporter to provide some information:
- domain: The affected domain of Sendinblue’s services (ex: API, Outbound Email Delivery, global, etc…)
- descriptive information: a summary and clear description explaining the situation (summary and description).
- impact: the number of clients affected by the outage. This information might be unknown at the time of the incident opening and filled in later.
- severity: long story short, how does it affect our customers’ business
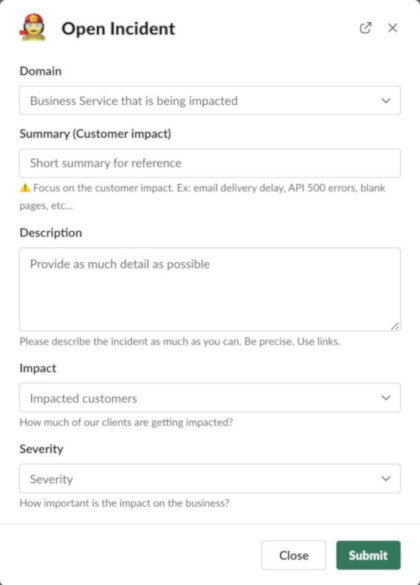
Later in the incident lifecycle, incident actors have the opportunity to provide more details about the incident (start date, notes, etc…)
On top of this information, given by stakeholders, every incident update or taken action leads to a database entry (events).
- MTTR(recovery) – Mean Time To Recovery, the time it takes to get the system back since the outage started.
- MTTA(acknowledge) – Mean Time To Acknowledge: the time it takes to get the incident from open to investigating state. Some situations may not be predictable and may miss proper monitors and alerts. The faster we get the alert and we get the expert in, the faster we can get the system back.
- MTTR(repair) – Mean Time To Repair, the duration it takes a domain expert to get the system in a normal state. It includes understanding the problem, identifying the root cause, and fixing the issue.
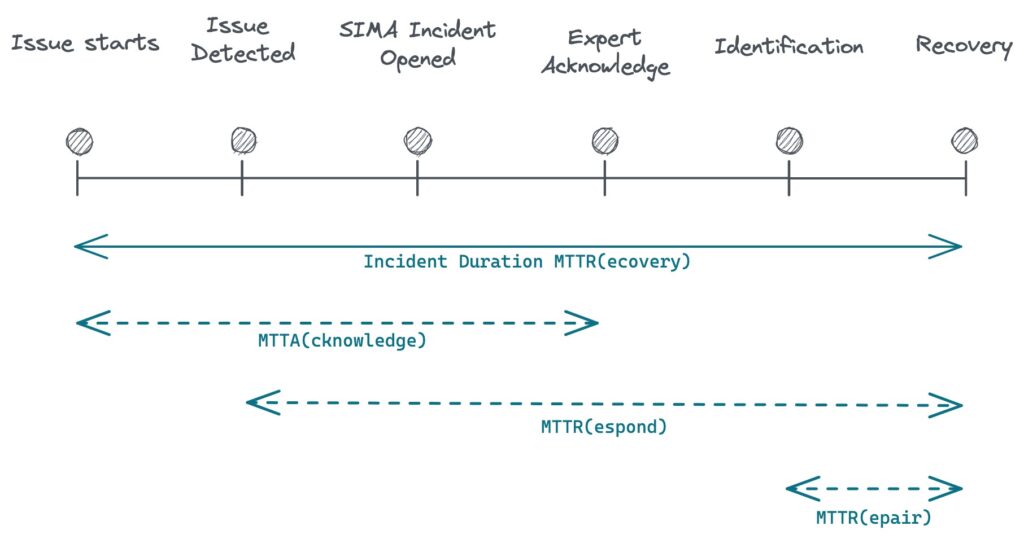
I highly recommend you to read the Atlassian’s if you want to learn more incident metrics: Common Metrics
At this point, we were able to generate precise metrics from events generated by SIMA’s users. We finally could improve our incident responses.
Improving the time to Acknowledge (MTTA)
Our system runs 24/7 and 365 days per year and has a direct impact on our customers’ business. They require experts to be available at any time in case of emergency. The faster you are able to get the right person to investigate the faster you reach the recovery state.
SIMA allows 2 ways of opening an incident:
- Slack app UI: anyone at the company can (theoretically) open an incident if the situation requires it. Most of the time, incidents are opened by engineers or Customer Care team members.
- Webhooks: we recently rolled out a way to open incidents from the outside of Slack. We’ve defined some monitors on critical aspects of Sendinblue (ex: Outbound Email Delivery, API) and expect them to open an incident automatically lowering the time to open the incident (and so the time to acknowledge)
Behind the scenes and as soon as an incident is opened, SIMA performs some actions in this order
- creates a dedicated slack channel (ex incident_MM_DD_summary-slug)
- we raised an alert on PagerDuty for the service (domain) impacted. The alert sent contains a deep-link to the slack channel, it lowers the time to join the conversation to its minimum.
Thanks to this, we are able to bring domain experts very quickly to an incident and make the MTTA as low as possible. The runbook we have is a bit more complex than these 2 steps but you understand that automating as much as possible is key to reactiveness.
Reducing the MTTR (Mean Time to Repair)
The time to repair period starts as soon as the incident is acknowledged. Different from the Time To Recovery, it focuses only on the operational part and calculates the time it takes to identify and fix the root cause.
A faulty release is trivial to roll back and should not take long as soon as it has been identified (most of the time 😉 ) but infrastructure outages can be tricky and complex to identify. An example comes to my mind where we lost a switch within a data center last year that lead to a full day of disruption .(We took concrete action, afterward, to make sure this issue does not happen in the future)
Our take on lowering the root cause finding: to provide our detectives the tools that would reduce the time to take the temperature
Easy access to information
Between the time, the expert receives the PagerDuty alert and the time they join the incident’s channel, SIMA executes some actions:
- share info in a dedicated channel: post a message in the incident channel (title, description, service, severity, and impact) and pin it within the channel
- invite stakeholders: at the moment only the reporter is invited as they may have more detail about the current issue. The on-call person will join soon after
- broadcast the incident: post a message within the company-wide channel dedicated to production issues (bots only)
These automated actions come in addition to slack commands we implemented
Having access to information is critical when you are under heavy fire, pushing the critical and most important one ensures our firefighters get up to speed as fast as possible
Defining roles
In order to keep things clean and organized, we’ve defined 2 roles (Inspiration: Roles and responsibilities)
- Incident Manager: in charge of driving efforts and people in the right direction, take the decisions to get the situation back to normal as fast and smoothly as possible.
- Communication lead: In charge of both internal and external communication, this person communicates with the Incident Manager allowing operational people to focus on what matters the most: recover
These roles have been in place for months and seem to be adopted. They prevent duplication of work and unknown performed in the dark actions. The incident manager drives the efforts and activities of people while the communication lead follows the situation and asks for clarification if needed.
Actionable in every situation
Messages with any Call To Action do not cut the mustard. Every event, actions, and messages are opportunities to save time and reduce the time to repair.
Example of CTA we display given situations:
When someone joins an incident’s channel:
- show help
- Become incident manager
- update incident state
- Show Incident info
- etc…
When someone mistypes a command:
- show help
- Show Incident info
- update incident state
- edit incident
- escalate
- etc…
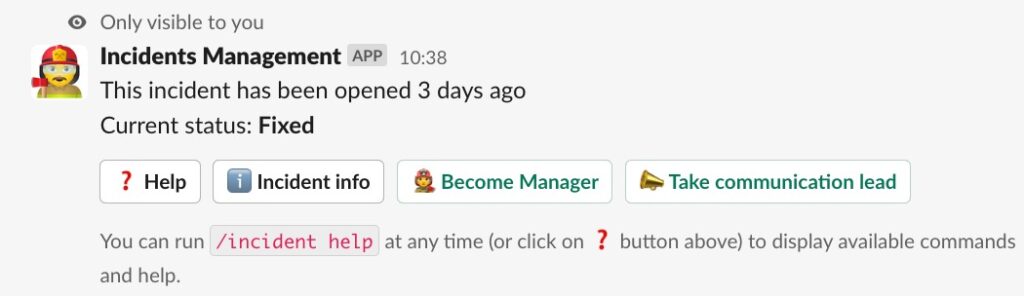
Adding relevant CTA, when the situation is suitable, increases user engagement and reduces human errors (read typos) and so frustration.
We highlighted some metrics we collect through SIMA to get better at incident responses. Measuring and automating was key in making the incident resolution as quick as possible.
The next section will drive us through the communication and analysis aspect
Incident management and beyond
Responding to an incident is no easy task and requires a lot of brain cells to make it a success.
We had to re-think the way we communicated, automated, and learned from incidents so that we became better at this exercise
Improving the communication
Before SIMA, slack threads and video calls were the way to go for bridging everyone. The incident communication was okay but we were missing an important part: the internal communication, between teams and stakeholders.
We focused on reducing the number of notifications sent and the cognitive load required to process the notifications
We defined different types of messages (and notifications), gave them one purpose, and made them easy to read (using a dedicated format for each message type):
- broadcast message: in order to keep everyone in the company aligned about current ongoing issues, SIMA posts a minimalistic message within an organization-wide and known channel
production-issues-bot. It gives everyone the global picture and the opportunity to jump into the dedicated channel easily - incident update message: Each time the Incident Manager (or communication lead) updates the incident status, SIMA saves the information into the database and posts 2 messages:
- An update – posted on the incident’s slack channel. Every stakeholder is on the same page.
- A reply – added to the broadcast message’s thread. People may subscribe to the broadcast message rather than join the war room. Broadcast messages see their content updated accordingly, keeping their content fresh.
- post-mortems: as soon as the situation goes back to normal and is considered stable, we generate and pre-fill a post-mortem on Notion. Similar to previous messages, post-mortems follow the same pattern (it evolved, during our journey, in favor of a lighter format). More on post-mortems later.
Each of these messages is generated by SIMA. They help involved people to focus on solving the problem rather than wasting time formatting messages. Thanks to the Slack Block API for making the formatting easy
Learning from incidents
How do we learn and improve from these incidents?
Post-mortems
Each incident, except in the case of false positives, gives place to a Post-mortem. The incident Manager, Communication lead, and some stakeholders regroup and collaborate to fill up the auto-generated post-mortem with various information.
Writing a post-mortem requires the team to step back and analyze the events and actions taken so that we become better and prevent a similar class of incidents to arise in the future.
Here’s an auto-generated post-mortem:
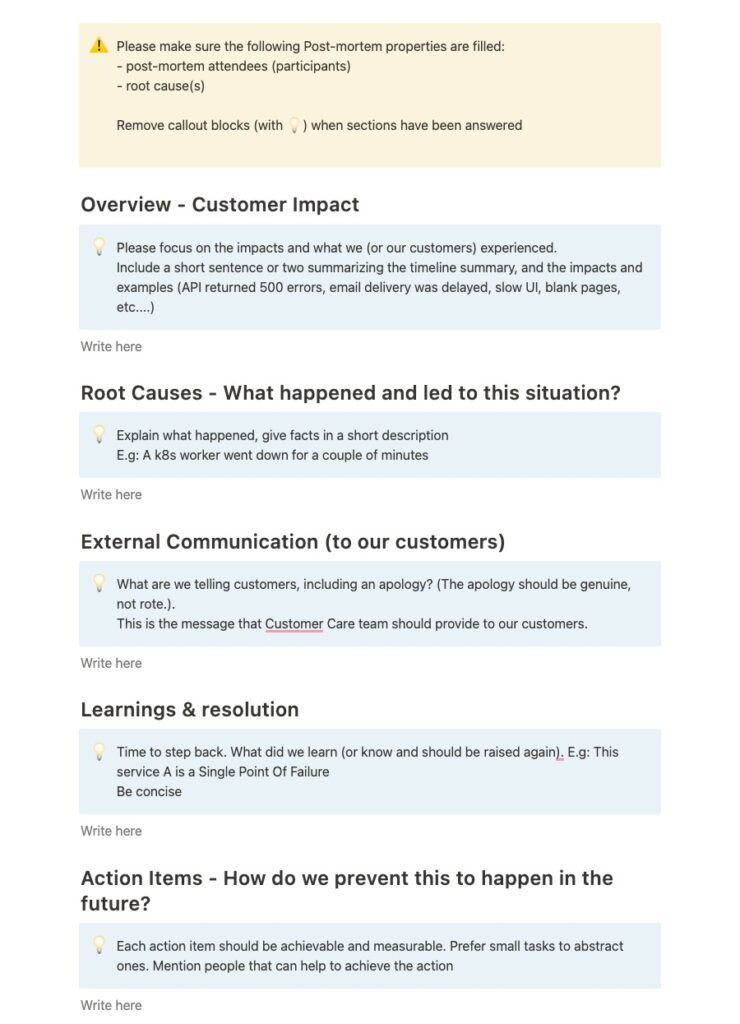
To make sure each incident has a positive impact on our company/products/methodology/culture, the team defines action items that we will plan and implement to become stronger than ever.
When finished, post-mortems are shared internally. They allow everyone in the company to find the information they need, either out of curiosity or because of a customer asking for detail.
Reading the numbers
SIMA started as a Proof Of Concept and slowly became an internal tool used by a lot of people. We are quite happy with the current implementation and will probably continue to tweak it.
We didn’t want to make this project a full-time job and took some shortcuts. One of these shortcuts was to not build any admin dashboard at first. In the beginning, we extracted data and numbers manually.
Today, there is no regret in making this decision. We rely on Metabase to analyze the metrics we collected. It helps us get the most of our data and build nice dashboards in a very short period of time.
We could have spent time building a UI to read and analyze our data but Metabase made the job very simple and allowed us to find bottlenecks faster than if we had built an in-house visualization tool.
Gather feedback
After we made the switch to the new incident response (SIMA) we started to gather feedback from incident stakeholders, the Customer-Care team, and engineers.
These feedback sessions were invaluable and in some part responsible for the success of SIMA. The customer care team helped us focus on different topics (ex: communication) and pushed SIMA to the next level, making the experience as clear and streamlined as possible
Do not underestimate teammates’ feedback
What did we learn/discover?
Building is easy
Building SIMA was the easiest part. If you ever used some APIs and are familiar with typescript or python or any language listed here https://api.slack.com/tools you should be able to build a working app in not much time (our first version was online after 1 week)
Once you get used to the Slack Block kit, you can achieve almost everything in slack.
Relying on API makes you move faster. Behind the scenes, SIMA interacts with Slack, PagerDuty, and Notion APIs. At the moment, we didn’t experience any issues
PagerDuty for the alerting, Firestore and Notion for the knowledge, Slack for the communication, and Metabase for the analysis is an excellent combo from our past experience
If you don’t have any resources don’t go down that path, if you have some it is definitely worth it.
Don’t expect people to use your product the way you imagined it
… unless you explicitly explain how it works
When rolled out SIMA noticed a couple of things:
- incident updates were uncommon
- post-mortem neglected
- unused/underused features
- etc…
We understood we missed an important part: Training
To bear the situation, we documented SIMA as if we were building the documentation for our customers.
- We included some decision trees (should they open an incident, update the status page, etc..)
- We listed all the commands and features available
- and added some examples
It could have been enough but we wanted more. We created a dedicated slack channel where people could find resources, ask questions or provide feedback. Every time we release a new feature(s), we post a message on this channel.
At the time of writing, we are releasing internally some lessons through Lessonly to ensure everyone in the company shares the same knowledge and understanding of what SIMA is for (including new joiners, maybe you? 🙂 )
Adoption is key
Rome wasn’t built in a day
Before we released it internally and communicated it to everyone, we put ourselves in the shoes of people working on both sides of the incident: Frontline and Backline.
Frontline, during an incident, is the Customer Care team. CC team receives and processes customers’ requests, and questions from different location whenever a problem arise (but not only)
The backline is most of the time, our engineering and infrastructure team.
Both sides, even if working for the same goal, have different expectations of the situation. Frontline expects communication updates and details to feed our customers’ questions. Backline expects system information, focus, and efficiency to diagnose and repair.
Communication between lines was very important and was the primary source of frustration. Being too pushy is equally inefficient as not communicating (from both sides)
As the primary objective is to get our customers successful, making the communication streamlined to get the most out of the situation became a piece of evidence.
The first incidents managed through SIMA were copies of slack thread but managed by the SRE team in the dark. Progressively, we introduced SIMA to people who became part of the experiment and later ambassadors. During this phase, we learned what every team was looking for (read information, updates, etc…). We drove each of our developments in a neutral and not (too :-P) opinionated way.
Finally, everyone has been participating in the development and evolution of SIMA in an equal way. Both sides suggested features and improvements that could benefit everyone.
Getting everyone to use and break SIMA was the best way to learn and improve our incident responses.
Conclusion
Nowadays, we consider SIMA as adopted. The number of incidents raised is growing and that is a good sign. It does not mean we have more production issues but people are confident that opening an incident will make us stronger than before. Even people not convinced, at the beginning of the project, are pushing SIMA to the forefront.
Building SIMA has been an incredible journey and it wouldn’t have been possible without the support of every team (and members) at Sendinblue.
Credits
We would like to Tarik and Jules for their contributions (development and reviews :-))